.png)
Inside Kernel engineering.
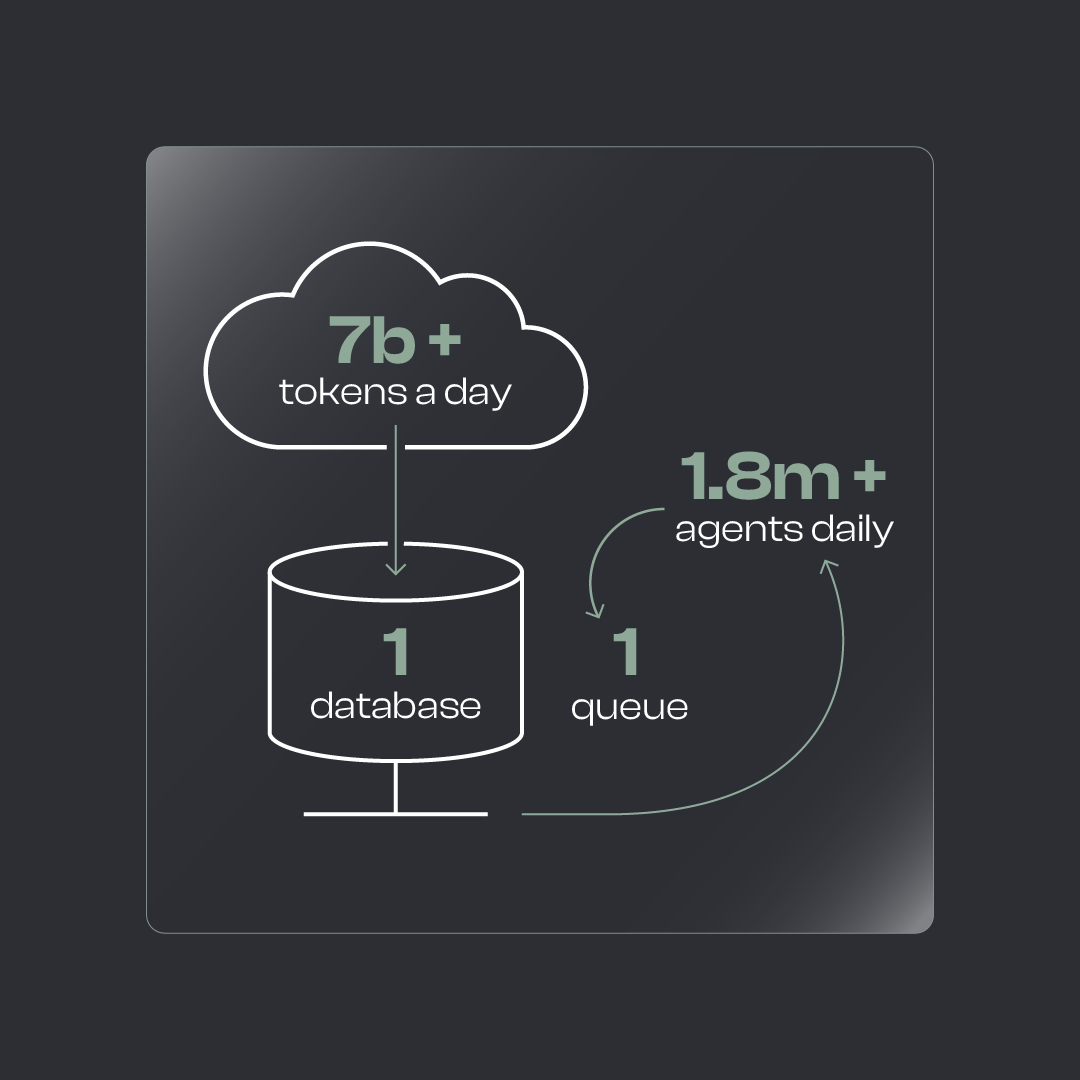
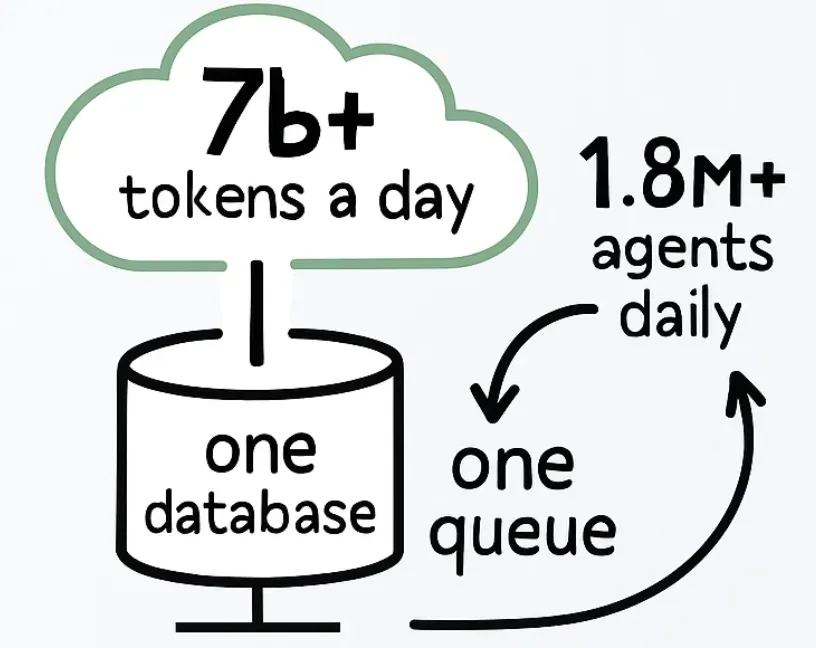
At Kernel, we process 7B+ tokens a day and run 1.8M+ agents daily, all on an architecture that’s intentionally simple: one database, one queue. It’s minimalism built for massive scale.
Simplicity doesn’t mean limits. We’ve stretched this foundation to power efficient web scraping, add deep configurability into the platform, and push LLMs into production at scale.

Why We’re Building Kernel
At its core, Kernel is an engineering problem: how do you map the world’s companies with enough accuracy, context, and scale that revenue teams can actually trust their CRM?
Every engineer knows the pain of dirty data. Duplicate entities, stale enrichment, and half-broken identifiers do more than slow down sales. They erode confidence in the systems we build. Most providers try to solve this with shortcuts such as generic enrichment, static firmographics, or one-size-fits-all datasets. The result is brittle systems that collapse under scale.
We chose a different path. Kernel is built around a context-rich company universe — a living graph of hierarchies, firmographics, and signals sourced from the open web and structured data. The real engineering challenge is not only achieving accuracy, but also keeping that universe fresh, complete, and queryable at scale.
That means:
- Designing pipelines that can clean and reconcile millions of accounts across sources.
- Building enrichment models that adapt to niche verticals and ICP definitions.
- Running LLMs and heuristics at scale without blowing up cost or latency.
- Creating APIs and interfaces that expose this power simply, without surfacing the underlying complexity.
In short: Kernel is what happens when you treat master data as a first-class engineering problem.
One DB to Rule Them All
At Kernel, the core is lean: one database, one queue.
That simplicity gives us:
- Predictability: one source of truth
- Speed: less coordination overhead
- Focus: solving customer problems, not wrestling infra
The trick is making it hold at scale. Billions of ops a day means constant tuning, pushing limits, and squeezing every drop out of the stack. It’s simple on paper and demanding in practice, but it lets a small team punch way above its weight.
Billions of Tokens Per Day
The numbers get big fast:

- Petabytes of messy data scraped, cleaned, and enriched
- ~7 billion tokens/day moving through our pipelines
For reference… Wikipedia has 2.3B tokens in the English wikipedia 🤯
- 1.8 million+ agents/day doing real work in production
at Kernel, an “agent” means a full end-to-end workflow execution that touches real customer data — not just a single API call
At this scale, nothing is ever “quiet.” Every second, something’s firing, merging, or retrying. The fun part isn’t just the raw throughput, it’s keeping the whole thing reliable without turning our infra bill into a horror story.
That means:
- Keeping latency low while juggling billions of ops
- Running and testing LLMs at scale while staying cost-aware
- Stretching a deliberately minimal core (one DB, one queue) into something that can carry enterprise workloads without flinching
Think of it less like a popcorn machine, more like a data factory running at full tilt and somehow still small enough for a team that fits around a single table.
Under the Hood: Where It Gets Interesting

Smarter Web Scraping
Scraping at scale usually means painful tradeoffs between cost, performance, and success rates. We’ve tuned our pipelines to be reliable and cheap enough to run every day.
- Smart retries that balance coverage with cost
- Site-specific strategies that don’t blow up infra spend
- Ongoing validation so signals stay fresh and usable
Configurable Agents
It’s not just about running agents, it’s about making them flexible. RevOps teams need to define ICPs in ways generic tools can’t, so we built:
- Control agents to orchestrate workflows
- Flows that string tasks together and validate end-to-end
- Composable functions (think Lego for ops logic)
LLMs at Scale
Running one model is easy. Running hundreds of variants across millions of agents is the real challenge. Our setup:
- Test multiple models against live traffic
- Track cost, latency, and quality in parallel
- Feed results back into planning so the system keeps improving
Smarter Classification
Classification sounds simple until you do it at messy, global scale. Our approach keeps it consistent and auditable.
- Dynamic schema generation for new verticals and ICPs
- Guardrails and backtesting for reliable results
- A mix of heuristics and LLMs for stability under load
For Customers Who Rely on Kernel
We work with some of the best revenue teams in the world. For them, Kernel isn’t just a tool — it’s their source of truth for market data. That makes the bar for engineering excellence extremely high.

